เนื่องจากที่บริษัทกำลังจะก้าวเข้าสู่โลก Big Data (จริงๆ เข้ามานานแล้วแหละ แต่เริ่มจะมีโอกาสได้ใช้ประโยชน์จากมัน) ช่วง 3-4 วันที่ผ่านมานี้ก็เลยมีโอกาสได้ลองแตะๆ Elasticsearch อยู่บ้าง จริงๆ มีอีกตัวหนึ่งที่คิดไว้คือ Solr แต่ส่วนตัวแล้วชอบชื่อ Elasticsearch มากกว่า ดูหล่อกว่า เลยเริ่มศึกษาจาก Elasticsearch ก่อน
Category: Research
หลักการทำงานของ MapReduce และตัวอย่างการใช้
มีโอกาสได้เริ่มอ่านหนังสือ Hadoop: The Definitive Guide เขียนโดย Tom White แบบจริงๆ จังๆ เพราะในอนาคตจะได้ใช้แน่ๆ กะว่าอ่านไปแล้วก็มาเขียนบล็อกแปลไปจะได้เข้าใจได้มากขึ้น โพสต์นี้จะกล่าวถึงหลัการทำงาน และตัวอย่างการใช้ MapReduce เพื่อประมวลผลข้อมูลจำนวนมหาศาล
MapReduce คือ programming model ที่จะแบ่งส่วนการทำงานเป็น 2 ขั้นตอน คือ ขั้นตอน map และ ขั้นตอน reduce โดยแต่ละขั้นตอนจะมีคู่ key-value เป็น input และ output ซึ่งเราจะเป็นคนกำหนดเอง ส่วนนี้อาจจะต้องอาศัยประสบการณ์เล็กน้อย และความเข้าใจในข้อมูลนั้นๆ ถึงจะออกแบบคู่ key-value ในแต่ละขั้นออกมาได้ สำหรับคนที่ยังมองไม่ออกก็ไม่เป็นไร ค่อยๆ ศึกษาไปเรื่อยๆ เดี๋ยวจะรู้เองครับว่าเราควรจะออกแบบออกมาแบบไหนถึงจะดี นอกเหนือจากการออกแบบแล้ว เรายังจะต้องกำหนดฟังก์ชั่น map และฟังก์ชั่น reduce อีกด้วย ว่าจะให้ทำงานอย่างไร
Continue reading "หลักการทำงานของ MapReduce และตัวอย่างการใช้"
A World Without Referees
ไปเจอบทความสั้นๆ ของ อ. Larry Wasserman (อ. ภาคสถิติที่ CMU) น่าสนใจดี
เค้าบอกประมาณว่าระบบ Peer review ที่ใช้กันอยู่ในปัจจุบันนี้ไม่สมควรจะมี เป็นเพราะว่างานวิจัยของเราเนี่ยควรจะเผยแพร่ให้มากที่สุดเท่าที่เป็นไปได้ ไม่ควรจะให้คนแค่ 2-3 คนมาปิดกั้นโอกาส ซึ่งบางทีก็ไม่ยุติธรรมถ้าคนเหล่านี้ตัดสินโดยใช้นำความรู้สึกมาเกี่ยวข้อง
อ. Larry ได้เสนอให้อัพโหลดงานเหล่านั้นขึ้นไปไว้บนเซิฟเวอร์ เช่น arXiv.org แล้วให้คนอ่านตัดสินกันเอง งานไหนดี ก็ได้รับความนิยม งานไหนไม่ดี ก็ได้รับคำวิจารณ์หรือไม่ก็โดนเพิกเฉยไป มีย่อหน้าหนึ่งในบทความนี้ที่ผมชอบ และขออนุญาตแปะไว้ที่บล็อกนี้ด้วย เชิญอ่านจ้า 😀
We should think about our field like a marketplace of ideas. Everyone should be free to put their ideas out there. There is no need for referees. Good ideas will get recognized, used and cited. Bad ideas will be ignored. This process will be imperfect. But is it really better to have two or three people decide the fate of your work?
ใครสนใจก็ลองไปอ่านฉบับเต็มกันได้ที่ [A World Without Referees]
My GSoC 2012 Proposal
This is my first attempt at Google Summer of Code (GSoC) 2012. I will propose my project idea to SimpleCV. I think it would be useful if I share my proposal here whether it will be accepted or rejected. 🙂 Anyway, you can find it [here].
Below is the quote from Anthony (one of the developers for SimpleCV) in pythonvision at googlegroups dot com. I would like to post it here, so readers can get the idea what SimpleCV is.
SimpleCV wrappers OpenCV amongst others. If you are new to computer vision it is probably worth a look as we have a bunch of examples: http://examples.simplecv.org
To be honest, that's how the whole SimpleCV project started. We got sick of their not being documentation, and were using other tools like ipython, etc, that we wanted integrated. We have also written our own blob detection library because we got sick of compile errors and having to use cvblob as a dependency.
We have a long way to go, and for seasoned vision programmers SimpleCV is probably not the route you want to go, if you are beginner it's definitely easier to get up and running. I wrote an article about the differences recently and I welcome any feedback: http://simplecv.tumblr.com/
post/19307835766/opencv-vs- matlab-vs-simplecv I think people get the misconception we are trying to replace opencv, and by no means is the case. We label ourselves as a framework not as a library. Think of us as a jquery or rails (ruby on rails) for vision. 🙂
Simple Linear Regression in Python
Linear regression เป็นการโมเดลข้อมูลโดยใช้ความสัมพันธ์เชิงเส้นที่มีตัวแปรตาม 1 ตัว และตัวแปรอิสระตั้งแต่ 1 ตัวขึ้นไป สิ่งที่เราจะต้องทำคือหาสมการเชิงเส้นที่เหมาะสมกับข้อมูลนั้นๆ ในบล็อกนี้จะกล่าวถึงแค่ simple linear regression ซึ่ง จะมีตัวแปรอิสระแค่ 1 ตัว แล้วเราจะได้สมการเชิงเส้นดังนี้
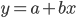
โดย y คือตัวแปรตาม (dependent variable) ส่วน x คือตัวแปรอิสระ (independent variable) ค่าสัมประสิทธิ์ (coefficient) a คือค่าของ y ตอนที่ x มีค่าเป็น 0 ดังนั้นเราสามารถเรียกได้ว่าเป็นจุดตัดแกน y หรือ y intercept นั่นเอง ส่วนค่าสัมประสิทธิ์ b คือความชัน (slope) ของเส้นตรงนั่น หรือค่าที่เปลี่ยนแปลงไปของ y เมื่อมีการเปลี่ยนแปลงที่ x ดูรูปข้างล่างนี้ประกอบ

สำหรับใครที่สนใจอยากรู้ว่าคำนวณอย่างไร ก็แนะนำให้อ่านการสอนของ Stefan Waner และการสอนของ Stephen Mak เพราะผมอ่านแล้วเข้าใจกว่าอ่านใน Wiki แหละ 😛
เอาล่ะ ไม่ต้องเขียนให้มากความ จัดโค้ดไปเลยดีกว่า ดาวน์โหลดได้ที่นี่ [Simple Linear Regression in Python] ข้างในจะประกอบไปด้วย 2 ไฟล์ดังนี้
- ไฟล์หลัก: main.py
- ไฟล์คลาส LinearRegression: linreg.py
โดยโปรแกรมจะคำนวณค่า a, b, coefficient of determination, coefficient of correlation, standard error of estimate, และ mean squared error of estimate ออกมาให้ครับ
โปรแกรมนี้เป็นโปรแกรมเกือบจะโปรแกรมแรกเลยที่เขียนด้วย Python เองเต็มๆ แบบว่าอยากทำงานและก็อยากศึกษาภาษาใหม่ไปด้วยในตัวก็เลยลองดู 🙂 เนื่องจากปกติเขียนแต่ภาษา C/C++ หรือ Java พอมาเขียน Python ก็เลยต้องเขียนไปบ่นไป ฮะๆ คิดว่าถ้าลองเขียนไปอีกสักพักน่าจะปรับตัวได้ แล้วก็ฝีมือในการเขียน Python ก็ยังอ่อนด้อยอยู่มาก ถ้าใครมีอะไรเพิ่มเติม ดุ ด่า เกี่ยวกับโค้ดก็ยินดีเลยครับ หรือจะเอาไปพัฒนาต่อก็ไม่ว่ากัน
ปล. โค้ดในบล็อกนี้แปลงมาจากโค้ด C++ ของ David C. Swaim II เกือบทั้งดุ้นเลยนะครับ หุหุ